Testing chatbots with chatbots

As a tester, I must admit my guilty pleasure back in late 2022 when ChatGPT-3 was released was finding screenshots of ChatGPT being broken. As people realized they could do wonders with this new toy — write essays, solve simple problems, generate code, enhance existing apps with new capabilities — we saw many examples of flawed reasoning and logical fallacies, factual errors, or even security hazards.
My personal favorite was when a user asked ChatGPT the name of the first woman president of the French Republic. The bot could not find one, so it confidently made one up.
There is now a technical term for this: hallucinations.
Now, the eventuality of having the bot hallucinate constitutes a big problem. On one hand, generative AI is a powerful tool that will carve its place into the industry and our livelihoods. And on the other hand, we need to keep in mind that AI can’t be blindly trusted.
Because when AI hallucinates, it does it with confidence, in a way that is often not obvious for users.
Which raises the question: how does one even test a chatbot?
Testing chatbots: A first look
How does one test a chatbot? The short answer: You test it by just talking to it, like a normal user would. As a manual tester, you will quickly notice that these tests are very time consuming, and that there is no manual way you can test the “truthfulness” of your AI-based chatbot thoroughly, given the infinite number of potential questions.
Hence the need for automation. Test automation offers many advantages, it allows us to test faster, and more systematically. We still will not be able to test thoroughly, but we will be able to test more.
To understand why, let us quickly go back to the basics of automated testing.
Schematically, automating tests is extremely simple: you want to test a system, it takes an input A, when it receives it, it outputs B. If it does not, the test fails. Your automated test provides input A, makes sure to trigger the system, then checks the output. Given-When-Then, Arrange-Act-Assert, call it what you will. What makes it simple — and therefore easy to automate — is the deterministic aspect of it.
The problem is, chatbots are non-deterministic systems:
- They receive input in natural language, which means two users are very unlikely to formulate the same question the same way.
- They spit out answers that are also in natural language. And since generative AI is trained to produce human-like behavior, that means if you ask the same question 5 times, it is unlikely you will get the same result 5 times.
Knowing this, automating tests on chatbots seems impossible on paper.
Or is it?
Test automation on chatbots
To sum it up, the problem we have with test automation and chatbots, is that test automation code is very deterministic by nature, and therefore unsuited to testing a chatbot.
Let us quickly summarize what blocks us from automating chatbot test cases:
- To emulate realistic inputs from users, we need the input prompts to be non-deterministic. In plain English, that means we need to reformulate our prompts with each test run.
- We need to find a way to validate what the chatbot answers. To an extent, that implies understanding what the chatbot writes.
We are in luck! We have a technology to work around this: Chatbots.
- Chatbots can be used to reformulate a prompt.
- Most importantly, chatbots can be used to “read” prompts
- Chatbots can evaluate if they match our expectations, and are truthful
We can easily sketch a solution, which would involve a “QA chatbot,” where the automation code is a mere relay between the two chatbots:
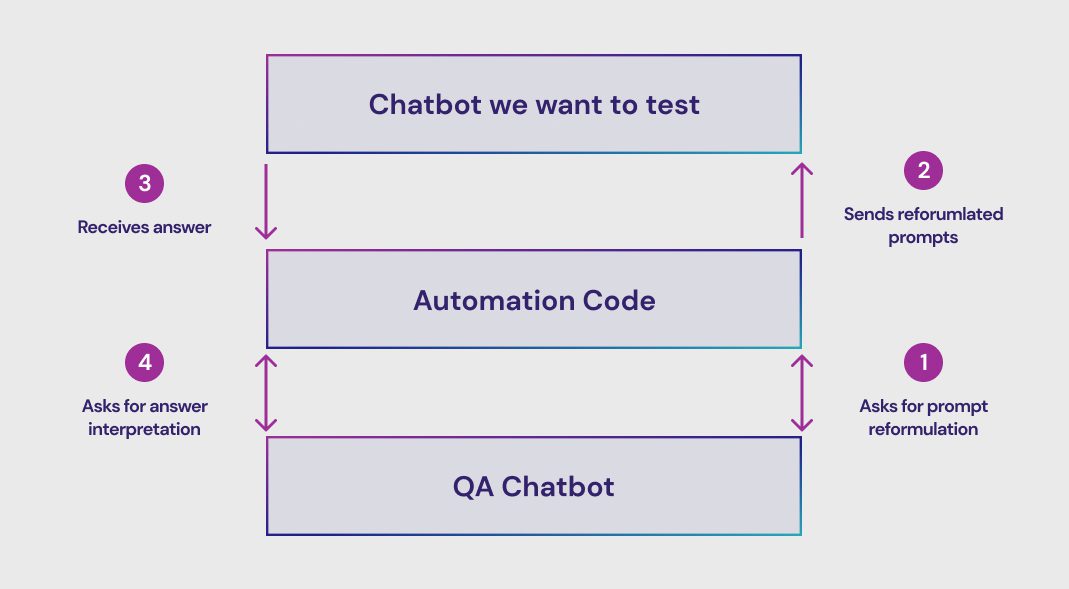
Implementing the solution
We have the idea, now let us see how to implement it. We will focus on how our QA chatbot helps us.
To emulate the behavior of a human user, we need to introduce some fuzziness in our inputs. That means that our automation code will have a base question, which will then be reformulated by the QA Chatbot. Then, we send the reformulated question to the tested chatbot.
Prompt reformulations
What is challenging is that we need the QA chatbot to return us something that is deterministic, so that we can parse the answer using our automation code. It is possible to influence most chatbots to return us a given format. The solution I chose is to ask for some python code containing the reformulations. Here is what it looks like:

This will make the QA Chatbot show us how to declare an array in python, containing the three reformulations. This format is easy to parse, even using deterministic code. Our automation code will then pick one of the three reformulations at random and send it to the chatbot we want to test.
Answer interpretation
The problem now is that the answer the automation code will receive is an answer which will be plain text, natural language. Depending on the chatbot we are testing, we may not be able to influence the format we are receiving.
This is why we need to ask our QA chatbot whether the response is valid or not. Here an example:
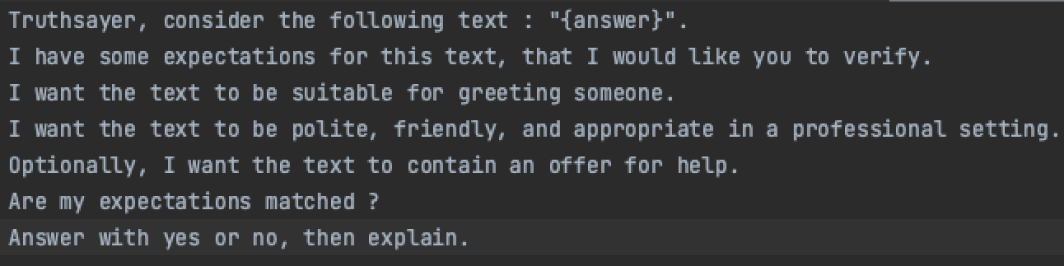
What you see above is a QA prompt. We insert the answer of the chatbot, then ask the QA chatbot that the answer matches a set of assertions Then, we tell the QA chatbot to answer by yes or no if the assertions are matched, this part is important, because our automation code will fail or pass the test depending on the first word of the response.
That prompt above is a very basic one, but it is also possible to check the truthfulness of an answer by mixing in deterministic elements in the prompt. Here is how it would work:
- Our automation code asks a question to the chatbot we want to test. The question may or may not have been reworded beforehand.
- Our automation code receives the response, then checks on its side what is the truth, using deterministic code.
- Our automation code generates and then gives the test chatbot a three-part prompt, which would follow this structure:
- Here is the context, and here is what I know is true
- Here is what was responded to me
- Would you say that the response I was given was truthful?
- Our automation code fails or passes the test, depending on the answer given by the test chatbot.
What makes this difficult to implement is finding good QA prompts. Which leads us to the next step.
Prompt-engineering our QA prompts
At this point, the concern people have is, how do you know the QA chatbot is working?
The answer is, we don’t trust the QA chatbot blindly. This is why engineering QA prompts is a slow and careful process.
What makes a good QA prompt:
- It does not confuse the chatbot.
- It detects anomalies.
- It does not fire false positives.
The process of engineering good prompts is difficult to describe in technical terms, because there is nothing technical about it. It is an iterative and exploratory approach, and you learn with experience what works and what doesn’t.
But then, how do we know what works? Short answer: We have a framework that tests the performance of each of our QA prompts, by comparing them to various answers (good and bad ones). When we reach a hallucination rate below a certain level, we consider that the QA prompt is ready.
We do this using a homemade framework, but this can also be achieved using Open-Source tools such as OpenAI-Eval.
Monitoring, evaluating truthfulness
Overall, the testing strategy yielded satisfying results, and allowed us to detect unwanted behaviors before we shipped our bot to production. But chatbots are complex systems that can’t be thoroughly tested, even with automated tests. Which is why we need to complement our “ante-mortem” approach with a “post-mortem” one.
In other words, we need not only to test, but also monitor the chatbot once it lands in production and interacts with real users.
To monitor the chatbot, we use a strategy that is very similar to what has been described before. We use an evaluator chatbot to assess that the interactions we have with actual users are matching truthfulness expectations.
Here is the gist of it:
- We scan all interactions for a given timespan.
- We feed these interactions to a chatbot that is specialized in assessing whether the responses are truthful or not.
- We use that data to improve our bot.
Conclusion
So far, this approach has shown promising results. We can detect anomalies both in pre-production by testing and post-production by monitoring. One could object to that method, by arguing that nothing proves that our QA chatbot is not hallucinating, but I would answer that this risk is mitigated by how we carefully forge our prompts. Besides, before I was testing chatbots with chatbots, I was testing software with software.
We should also acknowledge that what we are doing with chatbots is so far just the start of the journey. We are still talking about new technology and are very conscious of the risk involved. Which is why ION IQ never actually makes decisions on its own — humans are always involved — and is only used to better inform our customers.
And this is why we still do some manual testing, to complete the automated test runs. Human eyes still need to stay close.

Jérémy Gosselin
Test Automation Engineer
Jérémy Gosselin is a Test Automation Engineer at Ontinue. Originally trained as a developer, he developed a keen interest in testing and has since accumulated a decade of experience in this field, working in various industries. Beyond test automation, he was tasked with elaborating test strategies and serving as a mentor for best QA practices. Jérémy obtained his bachelor’s degree in software development from the University of Metz, in France.