A Technical Deep-dive into the ION IQ Bot
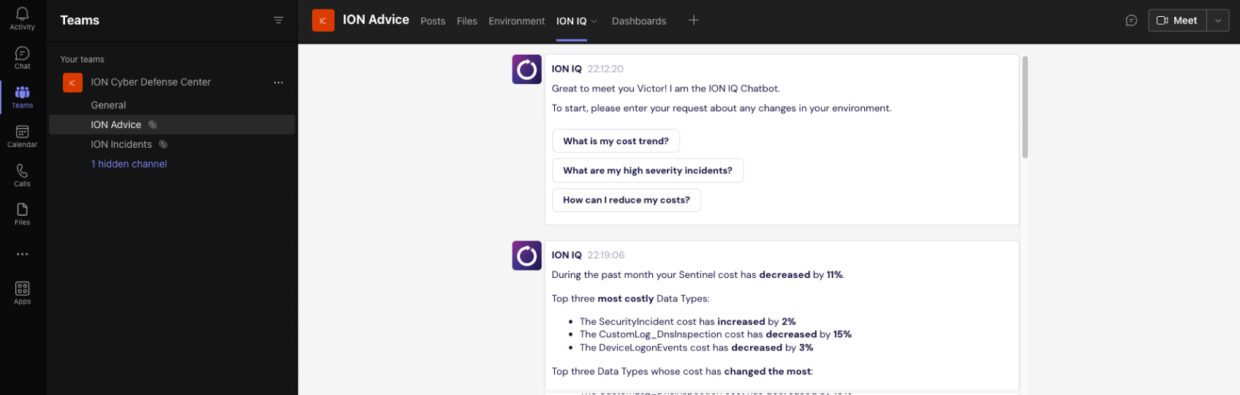
As mentioned in the previous post in our AI series, the recent fast improvements in the natural language area and in large language models (LLMs) have provided a modern and language-based way to communicate with users, overcoming some limitations of previous chatbots.
ION IQ leverages these technologies to provide a Bot that aims to improve the interaction of our customers with their security environments. It provides answers — based on a customer’s specific domain — to questions related to topics such as cost or security knowledge.
Below, we will explore the design principles and related implementation decisions taken to build the ION IQ Bot. Among the topics described are a focus on concepts related to localization, security and privacy and consistency — and how we aim to achieve them.
Implementation Decisions
Consistency
The ION Bot is built to limit one of the major weaknesses of LLMs: hallucinations. The Augmented Generation (AG) pattern, in conjunction with our implementation decisions, limits the possibility of hallucinations and blocks out-of-scope questions.
The AG pattern forces our Bot to rely on prompt engineering to include all the required information to answer questions. The prompts are carefully crafted to make effective use of such information and feed it to the pre-trained language model. This means that no fine-tuning or re-training of the model is required to produce answers or improve the service. The model used to power our Bot is the well-known1 GPT-3.5-turbo. This model combines a high completion speed with high reliability and a strong focus on structured prompting that matches our requirements.
A requisite to build a modern chatbot experience is the possibility to perform complex actions that involve collecting external data to answer questions. This requirement makes single LLM calls insufficient. We rely on the concept of Chains to provide such capabilities. An LLM-Chain contains one or multiple LLM calls and additional actions that are sequentially executed. As an example, replying to a question about the current weather requires a real-time data source, in addition to at least one LLM call, to produce a human-like answer.
To provide the desired consistency, the ION Bot also relies on the concept of Agents. Agents allow the LLM to decide which Chain (or Tool) is more suitable to answer specific questions by determining their intent and relevant input information. This concept provides an additional layer of control regarding when and which actions are executed. To build such Agents, we choose an open-source framework called Langchain2 with extensive capabilities and a large developing community.
Localization
The ION IQ Bot requires access to information about the environment of our customers to provide meaningful answers. Such data is retrieved on demand and fed into the LLM based on the AG pattern.

More extensively, the ION Bot requires access to:
- The LLM: the brain of the service
- A short-term memory required for follow-up questions
- A language detector to reply to questions in the customer’s native language
- A query library to access customer information required to answer questions. I.e., Microsoft Sentinel incidents and usage data
- A knowledge base with Ontinue expertise and curated Microsoft Security knowledge.
Providing expertise from an extensive knowledge base requires efficient methods to interact with LLMs, which have length constraints. We rely on the Retrieval Augmented Generation (RAG) pattern3 for such interaction. Like the AG pattern, RAG relies on prompt engineering to feed the context data to the model. This context is obtained by finding the most relevant pieces of information (documents) with respect to the question. For such a purpose, we use vector stores, which allow us to compute the distance between the latent representation (or embedding) of the question and the documents. This is the closest the most relevant a document is to provide a relevant answer.
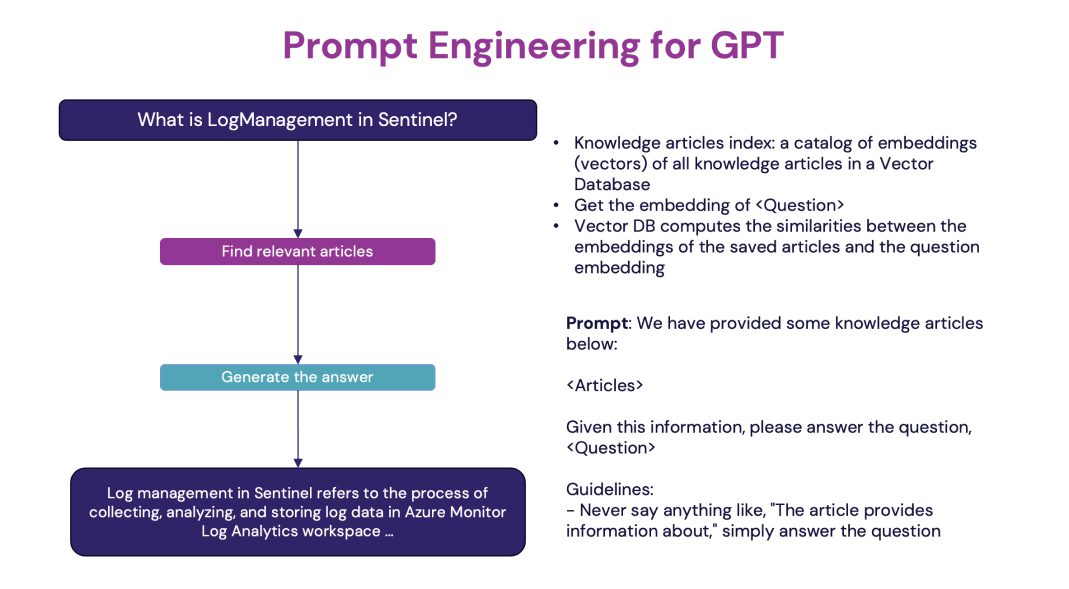
Privacy and Security
Our Bot has been designed to avoid possible data leakages or privacy holes. Which these requirements in mind, we selected Azure OpenAI as the deployment infrastructure for our language model.
Azure OpenAI ensures that model operations are stateless, meaning no data is stored during inference, and no data leaves the service boundary during any model operations. It is a cloud-native service that provides all the security capabilities offered in Azure and can be deployed in GDPR regions to fulfill the compliance requirements of our customers. This service also provides access to state-of-the-art language models built by a leading actor in the AI space, OpenAI.
Conclusion
In this post, we explored the choice of Azure OpenAI for security and privacy reasons. We investigated the AG pattern and the concepts of Chains and Agents to build a consistent Bot. And finally, we submerged on the topic of localization to introduce which data is required to provide a useful experience, including an overview on the RAG pattern and the concept of embeddings when dealing with a large knowledge base. All of our decisions are aimed at producing a secure, modern and localized experience for our customers, while trying to limit the challenges of LLM-based services, such as hallucinations or performance.
References
1 GPT-3.5-turbo is the default LLM model powering ChatGPT at the moment of writing this blog.
2 https://python.langchain.com/
3 https://colabdoge.medium.com/what-is-rag-retrieval-augmented-generation-b0afc5dd5e79

Sergio Roldan
Data Scientist
Sergio Roldan is a data scientist at Ontinue with more than two years of experience working on cybersecurity and machine learning related topics. He joined Ontinue as an intern for his thesis on Graph Neural Networks applied to the security field. Sergio has given talks in security and ML conferences such as CRITIS and AMLD, and he has published a paper in JCEN. He earned his Master in Cybersecurity from the two Swiss Federal Institutes of Technology (EPFL and ETHZ).